The internet has seen many resources come and go since its inception, but where do these resources go when they are long forgotten? I stumbled across the answer(to a certain extent) a while back, and decided to share it. Archive.org is an internet library of web resources, and is a pretty cool website to play around on.

At first, I was looking for something that archived web pages. Sure, you get googles page cache; but this only reveals the last snapshot, which may or may not be of any use. What I ended up finding, was The way back machine. More on the way back machine later. For now, I would like to go over some of the other cool features of The Internet Archive.

The internet archive turned out to be an archive for not only websites, but also video, audio, text, and software. Things I have not seen for years where right there, available for perusal. Founded in 1996, The Internet Archive has been receiving data donations for almost twenty years. Just like other libraries, The Internet Archive also provides facilities for disabled users, maximising their audience.
Video
The video collection is a catalogue of present and past clips, videos, and even full length feature films(most of which are from the golden days). The content ranges from animation, to community videos, as well as educational and music videos. If you recall a video you once watched, and would like to find it again, this could be the place you will find it.
Audio
Likewise with audio, the range of available resources are vast: audio books, poetry, music, podcasts and more.
Software
In the software category, the main attraction was the games archive. Not only were there an abundance of the ol’ computer games available, but there are also console games. Some of these older games also have a built-in emulator for you to play through your browser:

Games aside, there is also a shareware CD archive, and a whole host of console emulators.
Text
The text section has over 5 million books and articles from over 1500 curated collections. The variety available is immense, and I think every possible category is covered.

The way back machine
Last, but not least, is The wayback machine. You may wonder what relevance this has to security, but it does indeed have its place. During the reconnaissance phase of an attack, adversaries will attempt to learn as many details about their target as possible. One of these methods, is called foot printing. No amount of information is ever too much, as each piece of information may contribute to the inference of new ideas to tackle the problem. In this case, we have a mechanism that has archived website snapshots over a long period of time. Information a company may have had on their website in the past, could potentially be of assistance in building a profile about a company, its technologies, or its employees. This information could since have been removed from the website, when it became known that such information could be harmful to the company. I wont provide an example of such information, but I have no problem showing the capability of the way back machine, with this blast from the past:
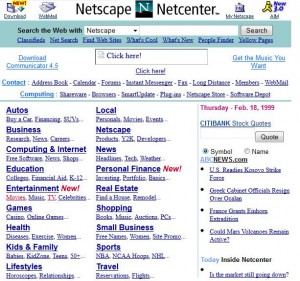
The way back machine is very useful for getting some historical context about a website, as well as the historical information that would come with it. Any snapshot ever taken by the way back machine is available for viewing, by selecting it on the time slider:

To conclude, I hope you check archive.org out, and trigger a bit of nostalgia. I am sure there is something there you will be interested to find.